Learning Objective
The objective of this SQL Server tutorial is to teach you about the nature and purpose of a clustered index.
What is an INDEX?
An index is a list of items ordered alphabetically or on some other ordering criteria so that the items and the information about the items can be accessed easily and quickly.
What is an INDEX in a database?
A database index also serves the same purpose as a normal index and allows us to access and retrieve a row of data in less time with less effort using lesser computing resources. The main purpose of an index is performance enhancement especially enhancing the performance of certain queries like SELECT, UPDATE, DELETE and MERGE. If a table has thousands of rows and there is no index SQL Server has to go through every row of data in the table until it comes across the required data. This process of looking up the entire table is called a table scan and is very resource intensive especially IO intensive. An index simplifies this process. If an index is in place for a table SQL Server queries the table through the index and utilizes the information in the index to get to the exact row in the table.
What is a CLUSTERED INDEX in SQL Server?
An index is an optional feature in SQL Server. It is possible to create a table in SQL server without creating an index if we do not specify a primary key while creating the table. If you do so the table data is physically stored in a HEAP. Simply put a Heap is a collection of rows or table records which is not sorted but stored the way it has been entered into the system. Creating an index on the table sorts the table records and the table is physically stored as the cluster indexed table instead of as a Heap.
An index can be created on both tables and views. Broadly speaking there are 2 main types of indexes in SQL Server – Clustered index and Non-Clustered Index. In this article we will be discussing only Clustered Index.
A clustered index is an index which is created by sorting a table or view on a key. The key is a column or a group of columns on which the sorting is done. By default, it is the table primary key which is used as the key for the clustered index.
A clustered index is a default phenomenon and there can be only one clustered index per table. This is because the rows in a table can be sorted in one way only once. A table having a clustered index is called a clustered table. To create a custom clustered index on a table we have to delete the existing default clustered index and then create one.
The term clustered is used in the name clustered index because usually connected or interrelated records are stored close together in the indexed table forming a bunch or cluster of similar records. Like for example if the key is a numeric column then the records are sorted and stored in ascending order. In such a scenario naturally 2 will be closer to 1 and 3. Another example can be of a table storing multiple choice questions with say 4 answer options. In such a scenario no matter in what order we make the entry or even after modification if the table is indexed on question number than all records (i.e. a question and its 4 answer options) for a question will be together making search and retrieval easy and fast.
SQL Server Clustered Index Example
Now let us see the practical implication and manifestation of the above concepts through an example.
A) Table Creation
First, we will create a table without defining a primary key so that there is no index created for the table. The following query will do the same and create a table called students but without a primary key.
CREATE TABLE students ( rollno TINYINT, firstname CHAR (50), lastname CHAR (50), stream CHAR (20) );
B) Data Insertion
After table creation we will insert some data into it using the following insert statement. Note that I have entered the records haphazardly and not in the order of roll numbers.
INSERT INTO students (rollno, firstname, lastname, stream) VALUES (23, 'Rizwan', 'Ahmed', 'Commerce'), (11, 'Amy', 'Williams', 'Arts'), (25, 'Nick', 'Jones', 'Science'), (13, 'Laura', 'Wells', 'Science'), (29, 'Michael', 'Bull', 'Science'), (33, 'Wayne', 'John', 'Commerce'), (35, 'Julie', 'Summers', 'Arts'), (30, 'Val', 'Kostner', 'Science');
c) Index Check
We will now check whether an index has been created on the table. The command to check the indexes associated with a table is the following.
EXEC SP_HELPINDEX 'schema_name.table_name';
In this command,
- SP_HELPINDEX is the system stored procedure to check indexes for the mentioned table.
In our case the command and its output is the below.
EXEC SP_HELPINDEX 'dbo.students'; The object 'dbo.students' does not have any indexes, or you do not have permissions. Completion time: 2020-09-26T23:38:21.6254082+05:30
We can see that there is no index associated with the table.
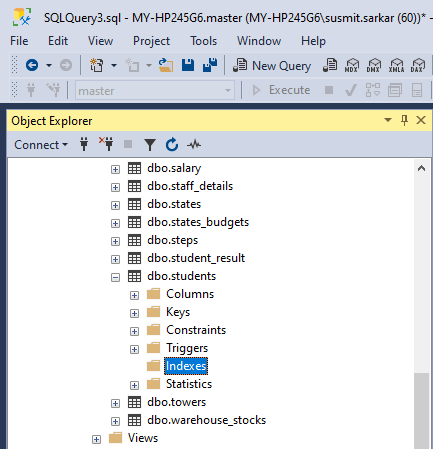
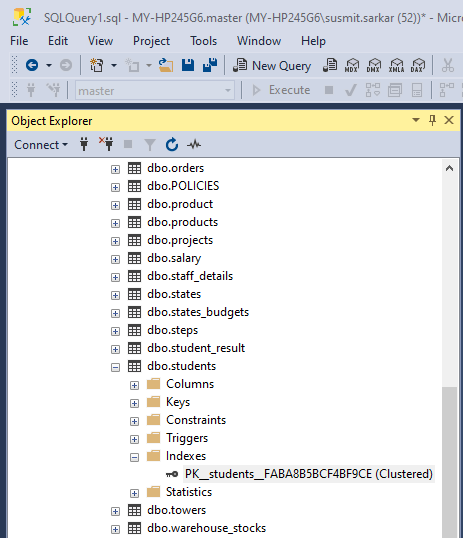
The same can be checked from the SQL Server Management Studio (SSMS) GUI as well. In the SSMS GUI Object Explorer expand Databases and then expand Tables. Select and expand the dbo.students table and under it and you can see the Indexes node. You can see all the indexes for a table here. But we can see that there is no index for our table. Refer figure below.
D) Querying Data
After checking and confirming the absence of an index for the table let us now run the following SELECT query to retrieve data from the table.
SELECT * FROM students;
It will generate the following output.
| rollno | firstname | lastname | stream |
| 23 | Rizwan | Ahmed | Commerce |
| 11 | Amy | Williams | Arts |
| 25 | Nick | Jones | Science |
| 13 | Laura | Wells | Science |
| 29 | Michael | Bull | Science |
| 33 | Wayne | John | Commerce |
| 35 | Julie | Summers | Arts |
| 30 | Val | Kostner | Science |
From the output we can see that it is unsorted and displaying in the order in which we entered the records. This is because the table has not been indexed and the table data structure is a Heap.
E) Checking Query Execution Plan
Also let us see the estimated query execution plan for the SELECT query. To see the query execution plan, click on the ‘Display Estimated Execution Plan’ button in SSMS tools menu or press Ctrl+L.
The execution plan will show in the bottom pane as shown in the figure below.
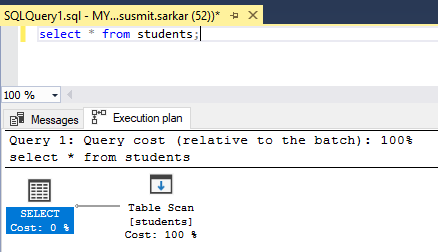
We can see that the execution plan uses a table scan.
F) Table Deletion and Recreation with Primary Key
We will now delete the table and recreate it with the rollno column as the primary key. The following queries do the same.
DROP TABLE students;
CREATE TABLE students ( rollno TINYINT PRIMARY KEY, firstname CHAR (50), lastname CHAR (50), stream CHAR (20) );
G) Checking Index
Let us now check the index status for the newly created table using SP_HELPINDEX and from the SSMS GUI as shown above. We can see that an index with the name ‘PK__students__FABA8B5BCF4BF9CE’ has been created as can be seen below.
| index_name | index_description | index_keys |
| PK__students__FABA8B5BCF4BF9CE | clustered, unique, primary key located on PRIMARY | rollno |
H) Data Insertion
INSERT INTO students (rollno, firstname, lastname, stream) VALUES (23, 'Rizwan', 'Ahmed', 'Commerce'), (11, 'Amy', 'Williams', 'Arts'), (25, 'Nick', 'Jones', 'Science'), (13, 'Laura', 'Wells', 'Science'), (29, 'Michael', 'Bull', 'Science'), (33, 'Wayne', 'John', 'Commerce'), (35, 'Julie', 'Summers', 'Arts'), (30, 'Val', 'Kostner', 'Science');
I) Querying Data
After data insertion we will run SELECT query for data retrieval.
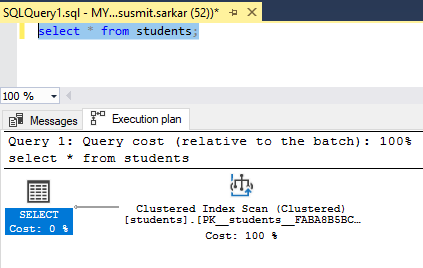
SELECT * FROM students;
It will generate the following output.
| rollno | firstname | lastname | stream |
| 11 | Amy | Williams | Arts |
| 13 | Laura | Wells | Science |
| 23 | Rizwan | Ahmed | Commerce |
| 25 | Nick | Jones | Science |
| 29 | Michael | Bull | Science |
| 30 | Val | Kostner | Science |
| 33 | Wayne | John | Commerce |
| 35 | Julie | Summers | Arts |
From the output we can see that the resultset is sorted on the rollno column. This is because of the default clustered index that has been created with the rollno key. The table data structure is not a Heap anymore but indexed and exists as a clustered table.
J) Checking query Execution Plan
Let us also examine the estimated query execution plan. We can see that this time the execution plan shows an index scan. So that is how a clustered index operates and facilitates faster and better query execution and data retrieval.