Learning Objective
The objective of this SQL Server tutorial is to teach you what is a unique index and how to create it on a table or view.
Introduction to SQL Server Unique Index
A unique index is an index with a unique key. A unique key is a key which comprises of a table column or a group of table columns which have unique values or a unique combination of values respectively. A unique index is automatically created in the background when we enforce the unique constraint on a column in a table. Otherwise it has to be created manually using a table column or group of columns with only unique values as the index key. If a column or any column in the group selected to be the index key has duplicate values the unique index creation will fail and once created successfully it will not allow the insertion of duplicate values in the key column or column group.
A unique index can be either clustered or non-clustered. If the primary key in a table has the unique constraint enforced on it then the default clustered index that is created on the primary key will be a unique clustered index. As with all indexes the purpose of creating a unique index on a table is to improve search and query performance by reducing the number of scans and replacing scans with seeks.
Operation
A unique index is created with the same index creation command but with the UNIQUE keyword in it which tells SQL Server to create a UNIQUE index.
SQL Server Unique Index Syntax
The basic syntax of the command to create a unique index is as follows.
CREATE UNIQUE INDEX
index_name
ON
table_name|view_name(column_list);
In this syntax,
- UNIQUE – keyword which tells SQL Server to create the new index as a unique index.
- table_name|view_name –the name of the table or view on which the unique index is to be created. It can be either one.
- column_list – A single column or two or more columns which constitutes the key for the new index.
SQL Server Unique Index Examples
We have a table in our customers which contains the basic information about customers. The table is represented below.
| customer_id | customer_name | customer_city | customer_email |
| 1 | Alicia Keys | Atlanta | alicia_alicia@gmail.com |
| 6 | Lauren Crow | Seattle | lcc2k02@gmail.com |
| 7 | Stephen Fleming | Seattle | fire_stephen_01@gmail.com |
| 12 | Rameses Williams | New York | WR04_04@yahoo.com |
| 13 | Stacey John | Atlanta | johnstaceyJSUS@hotmail.com |
| 14 | John Williams | Washington | J_will@yahoo.us |
| 15 | Kevin Spacey | New York | lblair90@yahoo.com |
| 16 | Linda Blair | New York | lblair90@yahoo.com |
We can see that the customer_email column in the table has duplicate values for the last 2 rows.
Checking uniqueness requirement
We will try to create a unique non-clustered index on the table using the customer_email column as the index key. The following command tries to the do the same and meets with an error. This is expected because of the duplicate value in the customer_email column. SQL Server will not allow the creation of a unique index on a key based on a column having duplicate values.
CREATE UNIQUE INDEX ix_custom_unique ON customers(customer_email); Msg 1505, Level 16, State 1, Line 4 The CREATE UNIQUE INDEX statement terminated because a duplicate key was found for the object name 'dbo.customers' and the index name 'ix_custom_unique'. The duplicate key value is (lblair90@yahoo.com). The statement has been terminated.
Making key column values unique
To be able to create a unique index we have to make all the column values unique. We do so by updating the customer_email value against the customer Kevin Spacey and making it kev_space@rediffmail.com. Below is the altered table.
| customer_id | customer_name | customer_city | customer_email |
| 1 | Alicia Keys | Atlanta | alicia_alicia@gmail.com |
| 6 | Lauren Crow | Seattle | lcc2k02@gmail.com |
| 7 | Stephen Fleming | Seattle | fire_stephen_01@gmail.com |
| 12 | Rameses Williams | New York | WR04_04@yahoo.com |
| 13 | Stacey John | Atlanta | johnstaceyJSUS@hotmail.com |
| 14 | John Williams | Washington | J_will@yahoo.us |
| 15 | Kevin Spacey | New York | kev_space@rediffmail.com |
| 16 | Linda Blair | New York | lblair90@yahoo.com |
Creating Unique Index
Now we run the above command again to create a unique non-clustered index with customer_email as the index key and it succeeds.
CREATE UNIQUE INDEX ix_custom_unique ON customers(customer_email); Commands completed successfully. Completion time: 2020-09 29T20:43:42.7400706+05:30
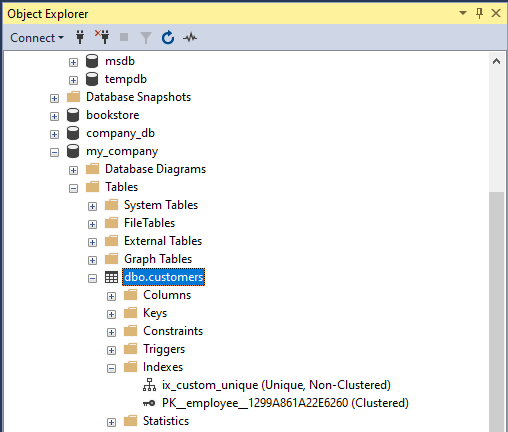
Checking the unique index
We can check the creation of the new unique non-clustered index using the below T-SQL command and from the SSMS GUI as shown below.
EXEC SP_HELPINDEX customers;
| index_name | index_description | index_keys |
| ix_custom_unique | nonclustered, unique located on PRIMARY | customer_email |
| PK__employee__1299A861A22E6260 | clustered, unique, primary key located on PRIMARY | customer_id |
Checking the Unique Index in Action
Finally, we try to insert the below record into the customers table. As you can see the query fails with duplicate key value error since it tries to insert the email id lblair90@yahoo.com as the customer_email which is a duplicate value.
INSERT INTO customers
VALUES
('Linda Smith', 'Atlanta', 'lblair90@yahoo.com');
Msg 2601, Level 14, State 1, Line 2
Cannot insert duplicate key row in object 'dbo.customers' with unique index 'ix_custom_unique'. The duplicate key value is (lblair90@yahoo.com).
The statement has been terminated.
Checking Benefit
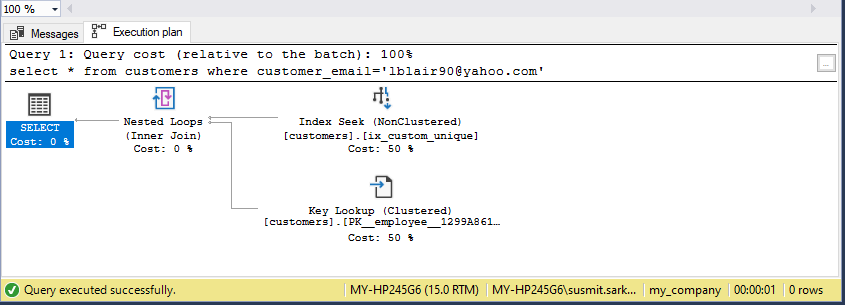
Now let us check the efficacy of the unique index we have created. We do so by generating the estimated execution plan for the below query.
SELECT * FROM customers WHERE customer_email='lblair90@yahoo.com';
To generate the estimated execution plan, click on the ‘Display Estimated Execution Plan’ icon or press Ctrl+L in SSMS. Below is the query execution plan which shows that the query processor will do a seek on the unique non-clustered index instead of a full table scan thus increasing the throughput and performance.