Learning Objective
The objective of this SQL Server tutorial is to teach you what is a filtered index, its benefits, and how to create one on a table.
What is SQL Server Filtered Index?
A filtered index is new type of index which was introduced in SQL Server from SQL Server 2008. A filtered index is an index which is created from a subset of the rows in a table instead of all the rows in the table. The subset of rows is derived by the filtration of a sparse column which is used as the index key. A sparse column is defined as a column which has less values or a column where some of the values are empty or NULL. The benefit of a filtered index is that it requires less space for storage as it is composed of only a subset of rows. The index scan and seek is also faster because of the same reason and hence it is more efficient in query processing.
Operation
A filtered index can only be created on a nonclustered index. The filtration of the index key column values is done with a WHERE clause.
SQL Server Filtered Index Syntax
The basic syntax of the command to create a filtered index is the same as that of normal index creation with the addition of the WHERE clause to filter the key column values to exclude or include rows where the values conform to the condition defined in the WHERE clause.
CREATE NONCLUSTERED INDEX index_name ON table_name(column_name) WHERE predicate;
In this syntax,
- NONCLUSTERED – this NONCLUSTERED keyword is optional. Even if nothing is specified SQL Server will interpret it as request to create a NONCLUSTERED index and create one.
- column_name – the index key column. It might be a single column or more than one.
- predicate – a logical expression/condition which the key column values must fulfil to be included in the index table.
SQL Server Filtered Index Example
Let us consider the below table called customer which contains basic customer information. The table is represented below. It has a column called contact containing customer phone numbers where available and NULL where not available. We will use this column to create our filtered index and understand its property and functionality. The custid column is the primary key with a default clustered index associated with it.
| custid | fname | lname | city | contact |
| 101 | Brian | Posey | New York | NULL |
| 102 | Sarah | Parker | New York | 16616165325 |
| 103 | Stephen | George | Washington | NULL |
| 104 | James | Mare | New York | 16277212992 |
| 105 | Angela | Crawford | Washington | 16633775159 |
| 106 | Selena | Spears | Detroit | NULL |
| 107 | Patty | Campbell | Detroit | 16107575525 |
| 108 | Brandon | Powell | Seattle | NULL |
| 109 | Kim | Fox | Washington | 16529929936 |
| 110 | Edith | Poe | Seattle | 16767335231 |
If we check the estimated query plan for the below SELECT query on the contact column, we will find that it uses a clustered index scan.
SELECT * FROM customer WHERE contact IS NOT NULL;
Query Execution Plan
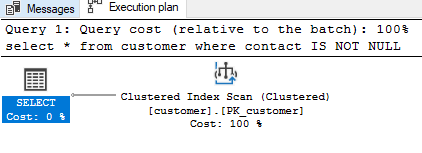
We know that a scan is costlier and slower as it has to go through all the records in the index or table. Indexes are created with the purpose of reducing the requirement for scans and replacing them with seek wherever possible. That is why we create multiple indexes with different keys for the most frequently accessed column data. We will do the same now and create a nonclustered index by filtering the non NULL rows in the contact column with the help of the filtered columns feature.
A) Creating the Nonclustered Index with Filtered Column
The below command created a nonclustered filtered index called ix_cust_contact on the customer table to make querying customer contact info easier and faster.
CREATE INDEX ix_cust_contact ON customer(contact) WHERE contact IS NOT NULL
We can check the creation of the new non-clustered index using the below T-SQL command and from the SSMS GUI as shown below.
Using T-SQL
EXEC SP_HELPINDEX customer;
| index_name | index_description | index_keys |
| ix_cust_contact | nonclustered located on PRIMARY | contact |
| PK_customer | clustered, unique, primary key located on PRIMARY | custid |
Using SSMS
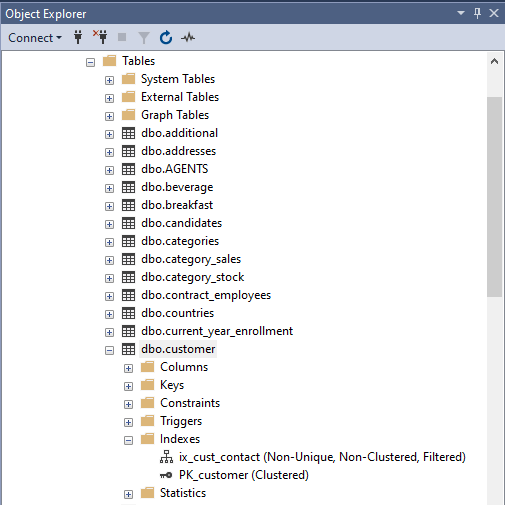
Checking the Filtered Index in Action
Now if we generate the estimated query plan for the above query it will be as below. This is different from the original query plan when the filtered index did not exist. With the filtered index in place, SQL Server uses an index seek of the filtered index to retrieve the values. From this, we can see the purpose and efficacy of using filtered indexes and how it can be used to improve performance at a nominal cost.
SELECT * FROM customer WHERE contact IS NOT NULL;
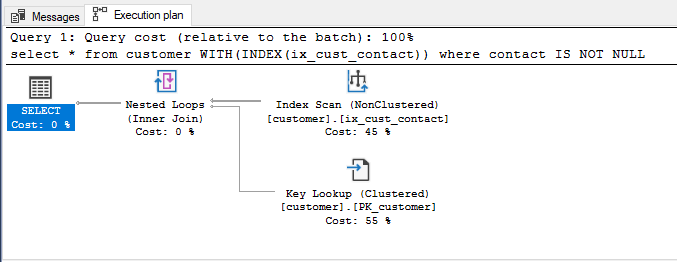
Query Result
| custid | fname | lname | city | contact |
| 107 | Patty | Campbell | Detroit | 16107575525 |
| 104 | James | Mare | New York | 16277212992 |
| 109 | Kim | Fox | Washington | 16529929936 |
| 102 | Sarah | Parker | New York | 16616165325 |
| 105 | Angela | Crawford | Washington | 16633775159 |
| 110 | Edith | Poe | Seattle | 16767335231 |