Learning Objective
The objective of this SQL Server tutorial is to teach you how to include non-key columns in an index to improve query performance.
What is SQL Server Index with Included Columns?
The ability to include additional non-key columns in an index to augment its capacity was introduced in SQL Server from SQL Server 2005. The inclusion of non-key columns benefits query processing by eliminating the need to consult multiple indexes or the main table. It does so by making all the relevant column data available in the index. Normally SQL server gets some of the required column values from the index and for the remaining column values it has to do a key lookup on the main table or the default clustered index which is costly both in terms of resources and time. An index including the relevant non-key columns eliminates that extra work.
Operation
An Index with Included Columns can only be created on a nonclustered index. The non-key columns which are included are those which are most frequently queried along with the key column.
SQL Server Index with Included Columns Syntax
The basic syntax of the command to create a non-clustered index including non-key columns is as below.
CREATE NONCLUSTERED INDEX index_name
ON table_name(column_list)
INCLUDE (included_column_list);
In this syntax,
- NONCLUSTERED – this NONCLUSTERED keyword is optional. Even if nothing is specified SQL Server will interpret it as request to create a NONCLUSTERED index and create one.
- column_list – comma separated list of key columns. It might be a single column or more than one.
- INCLUDE – SQL keyword to include additional columns in an index.
- included_column_list – comma separated list of additional or non-key columns. It might be a single column or more than one.
SQL Server Index with Included Columns Simple
Let us consider a table called customer which contains basic customer information. The table is represented below. The custid column in the table is the primary key and has a default clustered index associated with it. The email column contains customer email ids which is frequently queried and on which we will base our example.
| custid | fname | lname | city | contact | |
| 101 | Brian | Posey | New York | NULL | bposey@gmail.com |
| 102 | Sarah | Parker | New York | 16616165325 | sparker@gmail.com |
| 103 | Stephen | George | Washington | NULL | sg_wash@msn.com |
| 104 | James | Mare | New York | 16277212992 | jjameson19@gmail.com |
| 105 | Angela | Crawford | Washington | 16633775159 | angela2angel@msn.com |
| 106 | Selena | Spears | Detroit | NULL | spearss01@gmail.com |
| 107 | Patty | Campbell | Detroit | 16107575525 | camped_patty@msn.com |
| 108 | Brandon | Powell | Seattle | NULL | powellbb@gmail.com |
| 109 | Kim | Fox | Washington | 16529929936 | kimkimmy@gmail.com |
| 110 | Edith | Poe | Seattle | 16767335231 | epepp@msn.com |
Suppose we generate the estimated query execution plan for the below query to fetch a row of information for a particular customer with the email id ‘angela2angel@msn.com’.
Query
SELECT fname, lname, email
FROM customer
WHERE email='angela2angel@msn.com';
The query execution plan will be as below. We can see from it that it does an index scan of the default primary index which is the only index available.
Query Execution Plan

We know that a scan is costlier and slower as it has to go through all the records in the index or table. So to improve the situation we will create a non-clustered index including the fname and lname columns in the index.
Creating the Nonclustered Index with Included Columns
The below command creates a nonclustered index called ix_email_additional with the fname and lname columns included as non-key columns on the customer table.
Using T-SQL
CREATE NONCLUSTERED INDEX ix_email_additional
ON customer(email)
INCLUDE (fname, lname);
The same can also be created from the SSMS (SQL Server Management Studio) GUI in the following steps.
From SSMS
- Right click in the Index node under the customer table in Object Explorer and select New Index – > Non-Clustered Index.
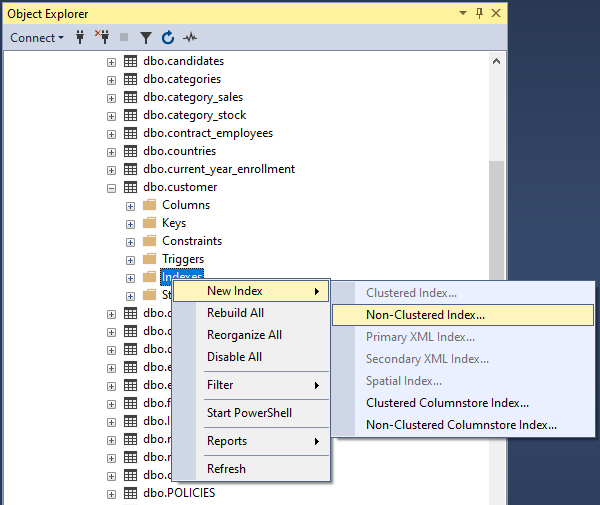
2) In the General tab of the New Index dialog box that will open, type in the name of the index in the Index Name textbox. Then go to the Index Key Columns tab on the middle of the dialog and add the key column email using the Add button on the right as shown in the figure below.
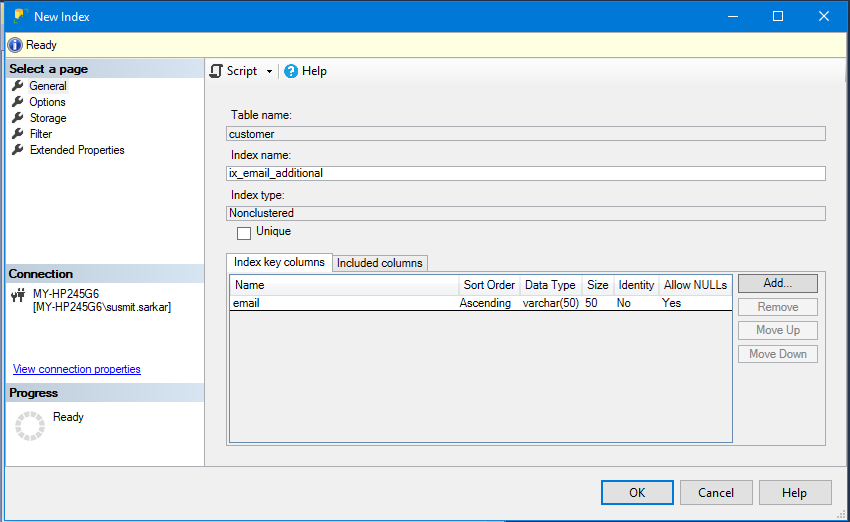
3) Once added it will show in the window as below.
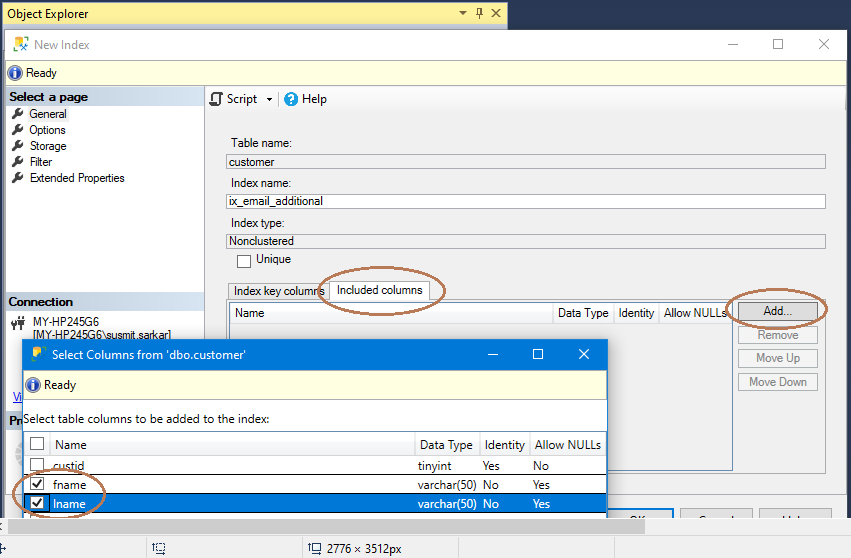
4) Then go to the Included Columns tab and add the fname and lname column by clicking on the Add button in the exact same manner as you did before.
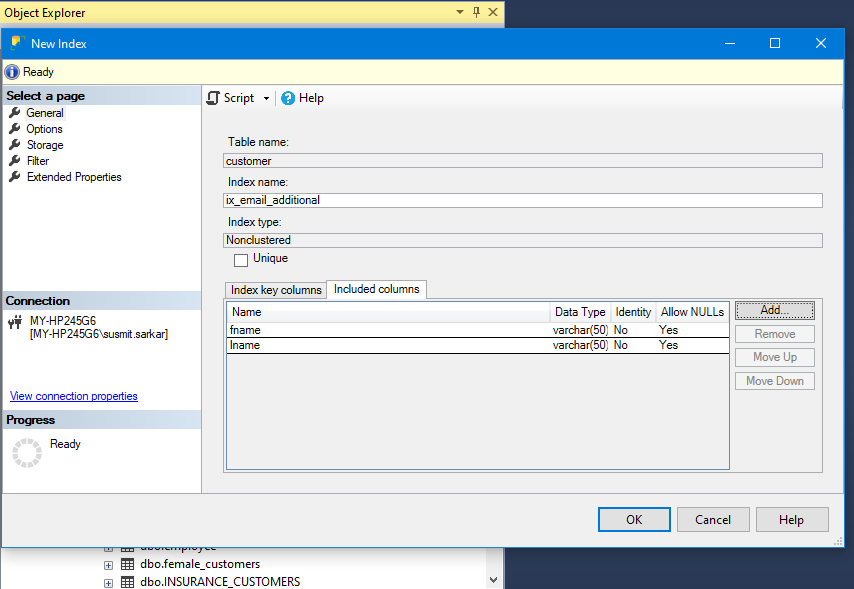
5) Once added it will show up in the main dialog. You can then complete the process by clicking on the OK button to create the new non-clustered index with the selected non-key columns and it will be created.
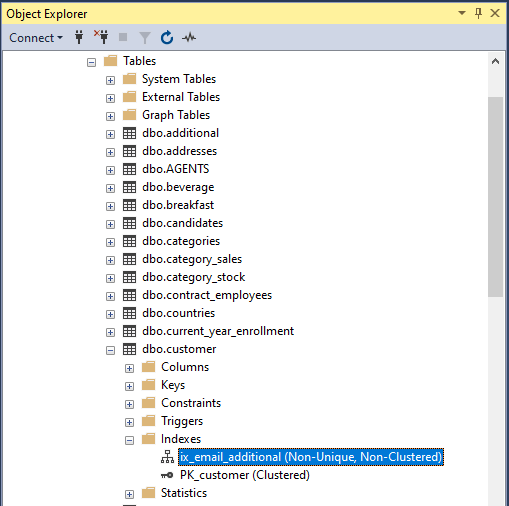
You can check the newly index using below T-SQL command or from the SSMS GUI as follows.
Using T_SQL
EXEC SP_HELPINDEX customer;
| index_name | index_description | index_keys |
| ix_email_additional | nonclustered located on PRIMARY | |
| PK_customer | clustered, unique, primary key located on PRIMARY | custid |
Using SSMS
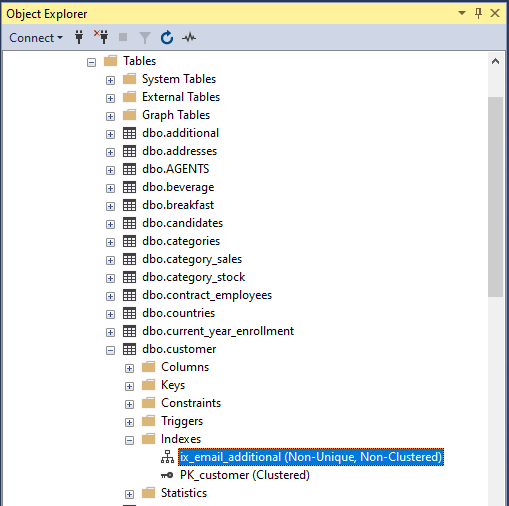
Checking the New Index in Action
Now let us generate the estimated query execution plan for the above query with the new index in place. As we can see from the screenshot this time the query execution plan is different and it is using an index seek on the newly created non-clustered index with included columns. So we can see the difference it makes.
Query Execution Plan
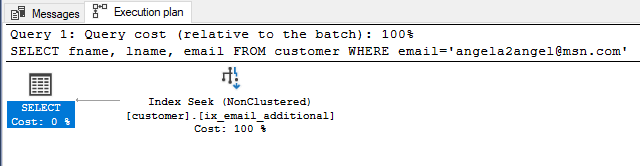
Getting things in perspective
However, if we change the query as below and generate the query execution plan for the same, we will see a different plan.
SELECT * FROM customer WHERE email='angela2angel@msn.com';
Query Execution Plan
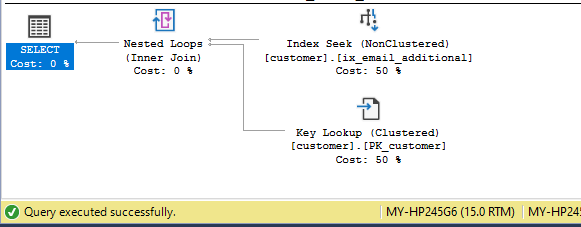
In the above plan we can see that SQL Server will first do a seek on the non-clustered index with the included columns and then it will do a key lookup (i.e. lookup required columns values corresponding to the key from another index or the main table where the data exists) on the default clustered index. This is because the non-clustered index does not contain the values for the other columns (i.e. city, contact) required by the query as the query is a SELECT * query to fetch the column values of all columns for customer with email id ‘angela2angel@msn.com’. The query result is displayed below.
Query Result
| custid | fname | lname | city | contact | |
| 105 | Angela | Crawford | Washington | 16633775159 | angela2angel@msn.com |